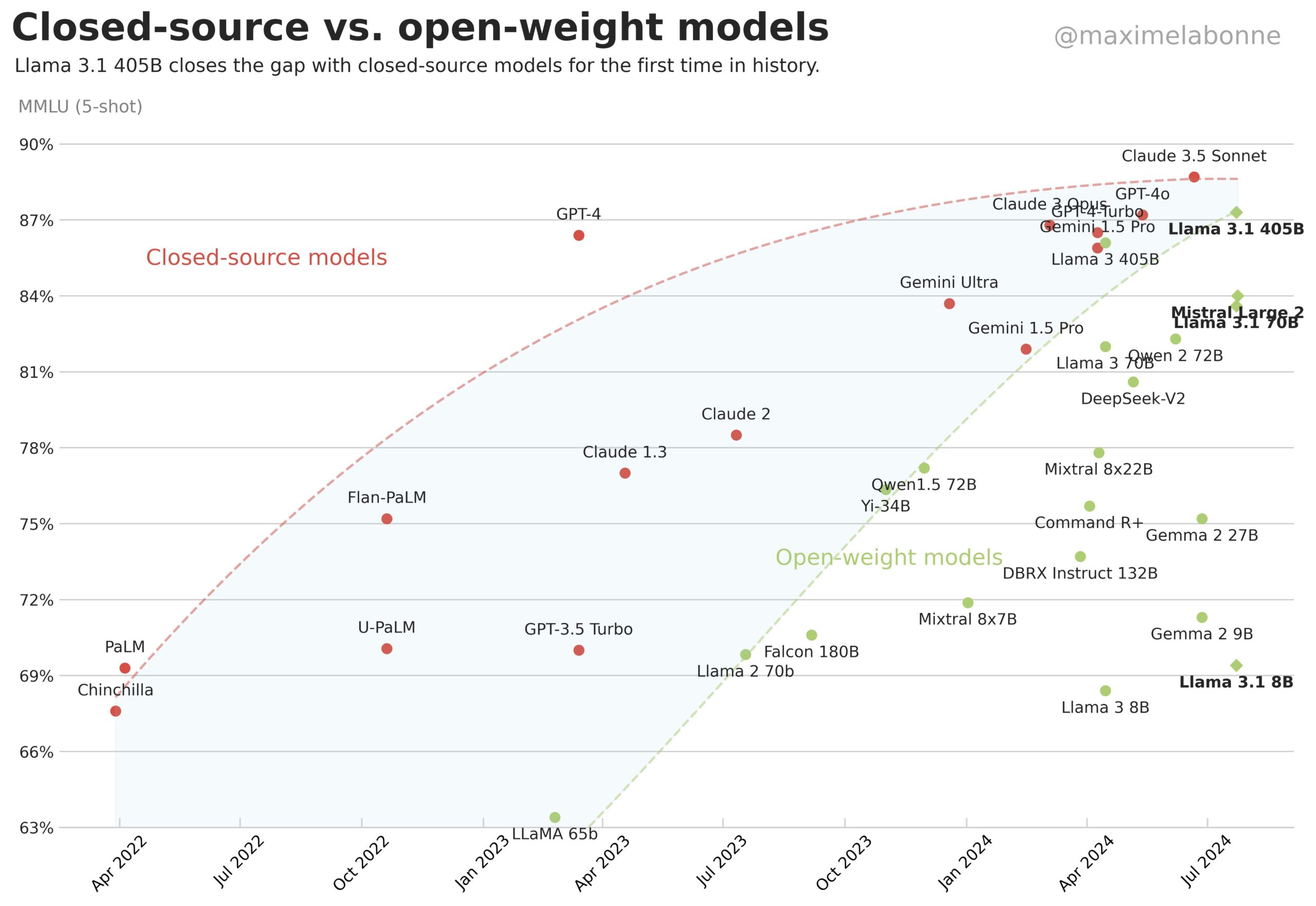
Het nieuwe “Orion”-model van OpenAI laat naar verluidt kleine winsten zien ten opzichte van GPT-4
De ontwikkeling van taalmodellen lijkt een plafond te hebben bereikt. Volgens een nieuw rapport presteert het aankomende Orion-model van OpenAI nauwelijks beter dan GPT-4, zijn voorganger. Deze vertraging heeft gevolgen voor de hele AI-industrie.
De informatie meldt dat OpenAI's volgende grote taalmodel, met de codenaam “Orion”, levert veel kleinere prestatiewinst op dan verwacht. De kwaliteitsverbetering tussen GPT-4 en Orion is opmerkelijk minder belangrijk dan wat we tussendoor zagen GPT-3 en GPT-4.
Bovendien verslaat Orion zijn voorganger niet consequent op gebieden als programmeren, en laat hij alleen verbeteringen zien in de taalmogelijkheden, volgens de bronnen van The Information. Het model zou ook duurder kunnen zijn om in datacenters te draaien dan eerdere versies.
Geen trainingsmateriaal meer
OpenAI-onderzoekers wijzen op onvoldoende trainingsgegevens van hoge kwaliteit als een van de redenen voor de vertraging. De meeste openbaar beschikbare teksten en gegevens zijn al gebruikt. Als reactie hierop heeft OpenAI een ‘Foundations Team’ opgericht onder leiding van Nick Ryder, zo meldt The Information.
Advertentie
Dit komt overeen met de verklaring van CEO Sam Altman in juni dat, hoewel er voldoende gegevens beschikbaar zijn, de focus zal verschuiven naar meer leren met minder data. Het bedrijf is van plan synthetische data (trainingsmateriaal gegenereerd door AI-modellen) te gebruiken om deze kloof te helpen overbruggen.
De informatie merkt op dat Orion al gedeeltelijk heeft getraind op synthetische gegevens van GPT-4 en OpenAI's nieuwe “redeneermodel” o1. Deze aanpak brengt echter het risico met zich mee dat het nieuwe model simpelweg “in bepaalde aspecten op die oudere modellen lijkt”, aldus een medewerker van OpenAI.
LLM-stagnatie vormt een uitdaging voor de sector
De vertraging in de LLM-vooruitgang gaat verder dan OpenAI. The Verge meldde onlangs dat Google's aankomende Gemini 2.0 niet voldoet aan de interne doelstellingen. Het gerucht gaat dat Anthropic de ontwikkeling van versie 3.5 van zijn vlaggenschip Opus heeft stopgezet en in plaats daarvan een verbeterde Sonnet heeft uitgebracht – mogelijk om teleurstellende gebruikers en investeerders te voorkomen.
Open-sourcemodellen die de afgelopen achttien maanden de eigen modellen van een miljard dollar hebben ingehaald, laten dit sectorbrede plateau verder zien. Deze vooruitgang zou onwaarschijnlijk zijn als grote technologiebedrijven hun enorme investeringen effectief zouden kunnen omzetten in betere AI-prestaties.
Maar in een recent interview zei OpenAI-CEO Sam Altman bleef optimistisch. Hij zei dat de weg naar kunstmatige algemene intelligentie (AGI) duidelijk is, en dat wat nodig is een creatief gebruik van bestaande modellen is. Altman zou kunnen verwijzen naar de combinatie van LLM's met redeneringsbenaderingen zoals o1 en agentische AI.
Noam Brown, een prominente AI-ontwikkelaar bij OpenAI en voormalig Meta-medewerker die hielp bij het creëren van o1, zegt de verklaring van Altman weerspiegelt de mening van de meeste OpenAI-onderzoekers.
Het nieuwe o1-model heeft tot doel nieuwe schaalmogelijkheden te creëren. Het verschuift de focus van training naar gevolgtrekking: de rekentijd die AI-modellen nodig hebben om taken te voltooien. Bruin gelooft deze aanpak is een “nieuwe dimensie voor schaalvergroting.”
Maar het zal miljarden dollars en een aanzienlijk energieverbruik vergen. Dit is een belangrijke vraag voor de sector voor de komende maanden: is het bouwen van steeds krachtigere AI-modellen – en de enorme datacenters die ze nodig hebben – economisch en ecologisch zinvol? OpenAI lijkt dat te denken.
Gemini-LLM in AlphaProof was “in wezen cosmetisch”
Google AI-expert François Chollet bekritiseerde het schalen van taalmodellen voor wiskundige taken. Hij noemde het “bijzonder stompzinnig” om vooruitgang in wiskundige benchmarks als AGI-bewijs aan te halen.
Chollet betoogt dat empirische gegevens aantonen dat diepgaand leren en grote taalmodellen wiskundige problemen niet zelfstandig kunnen oplossen. In plaats daarvan hebben ze discrete zoekmethoden nodig: systematische benaderingen die verschillende oplossingspaden controleren in plaats van waarschijnlijke antwoorden te voorspellen, zoals taalmodellen dat doen.
Hij had ook kritiek op het gebruik van ‘LLM’ als marketingterm voor alle huidige AI-ontwikkelingen, zelfs als deze geen verband houden met taalmodellen. Hij wees op de integratie van Gemini in AlphaProof van Google Deepmind als “in wezen cosmetisch en voor marketingdoeleinden.”



